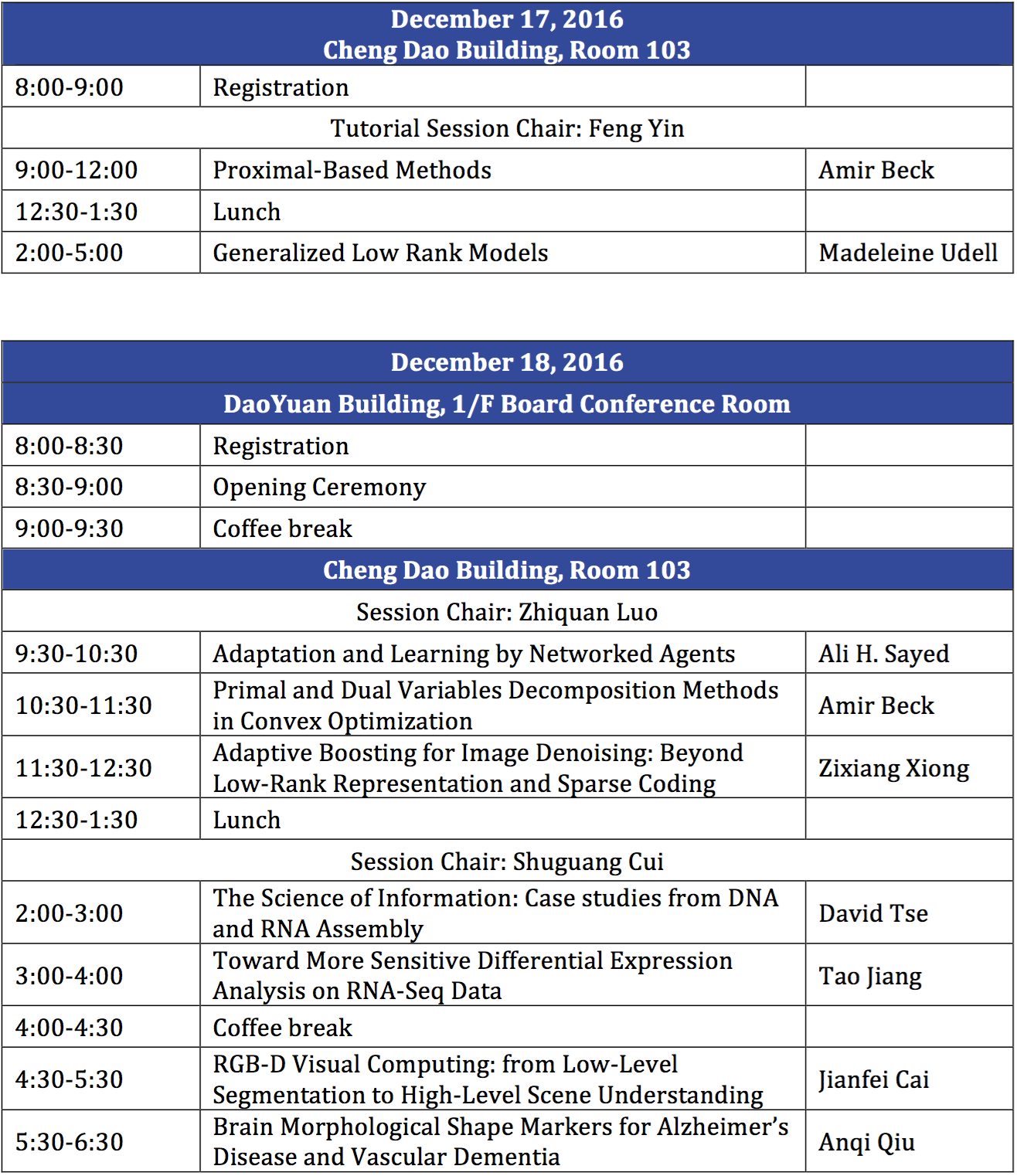
Technical Program
The Registration is open on December 16, 18:00 - 20:00, at DaoYuan Building Lobby.
 |
 |
Tutorials
Proximal-Based Methods
 |
Amir Beck |
Proximal-based methods are recognized as effective methods for solving large-scale problems arising from different applications areas. This tutorial lays out the basic theoretical background needed to understand proximal-based methods, including the basic properties of the proximal mapping, as well as fundamental inequalities that are essential to proving complexity results. We will explore several algorithms including proximal (sub)gradient, dual proximal gradient, FISTA, smoothing, block proximal and ADMM.
Generalized Low Rank Models
 |
Madeleine Udell |
Modern data sets are often big and messy: they may feature a mixture of real, boolean, ordinal, and nominal values; and often many (or even most) of the values of interest are missing. In this talk, we introduce Generalized Low Rank Models (GLRMs), a class of optimization problems designed to uncover structure in big messy data sets. These models generalize many well known techniques in data analysis, such as (standard or robust) PCA, nonnegative matrix factorization, matrix completion, and k-means. We'll show how to use GLRMs to impute missing values; to design recommender systems; to and to perform dimensionality reduction; all in a setting with heterogeneous and missing data.
The resulting optimization problems are nonconvex, nonsmooth, and often have millions or even billions of parameters. We'll discuss efficient optimization techniques for these problems, and ways of exploiting parallelism to improve runtime.
Invited talks
Adaptation and Learning by Networked Agents
 |
Ali H. Sayed |
Network science deals with issues related to the aggregation, processing, and diffusion of information over graphs. While interactions among agents can be studied from the perspective of cluster formations, degrees of connectivity, and small-world effects, it is the possibility of having agents interact dynamically with each other, and influence each other's behavior, that opens up a plethora of notable possibilities. For example, examination of how local interactions influence global behavior can lead to a broader understanding of how localized interactions in the social sciences, life sciences, and system sciences influence the evolution of the respective networks. In this presentation, we examine the learning behavior of adaptive networked agents over both strongly and weakly-connected graphs. The discussion will reveal some interesting patterns of behavior on how information flows over graphs. In the strongly-connected case, all agents are able to learn the desired true state within the same accuracy level, thus attaining a level of “social equilibrium,” even when the agents are subjected to different noise conditions. In contrast, in the weakly-connected case, a leader-follower relationship develops with some agents dictating the behavior of other agents regardless of the local information clues that are sensed by these other agents. The findings clarify how asymmetries in the exchange of data over graphs can make some agents dependent on other agents. This scenario arises, for example, from intruder attacks by malicious agents, from the presence of stubborn agents, or from failures by critical links.
Primal and Dual Variables Decomposition Methods in Convex Optimization
|
|
Amir Beck |
In recent years, due to the “big data” revolution, large-scale and even huge-scale applications have started to emerge, and consequently the need for new, fast and reliable decomposition methods has become evident. We consider a class of block descent methods that involve the solution of many simple optimization subproblems of small dimension in place of the original problem. Rates of convergence of different variants will be presented and the dual functional form will be explored.
Adaptive Boosting for Image Denoising: Beyond Low-Rank Representation and Sparse Coding
 |
Zixiang Xiong |
In the past decade, much progress has been made in image denoising due to the use of low-rank representation and sparse coding. In the meanwhile, state-of-the-art algorithms also rely on an iteration step to boost the denoising performance. However, the boosting step is fixed or non-adaptive. In this work, we perform rank-1 based fixed-point analysis, then, guided by our analysis, we develop the first adaptive boosting (AB) algorithm, whose convergence is guaranteed. Preliminary results on the same image dataset show that AB uniformly outperforms existing denoising algorithms on every image and at each noise level, with more gains at higher noise levels.
The paper has been awarded the Best Paper Prize for Track: Image, Speech, Signal and Video Processing at ICPR2016.
The Science of Information: Case studies from DNA and RNA Assembly
 |
David Tse |
Claude Shannon invented information theory in 1948 to study the fundamental limits of communication. The theory not only establishes the baseline to judge all communication schemes but inspires the design of ones that are simultaneously information optimal and computationally efficient. In this talk, we discuss how this point of view can be applied on the problems of de novo DNA and RNA assembly from shotgun sequencing data. We establish information limits for these problems, and show how efficient assembly algorithms can be designed to attain these information limits, despite the fact that combinatorial optimization formulations of these problems are NP-hard. We discuss Shannon and HINGE, two de novo assembly software designed based on such principles, and compare their performance against state-of-the-art assemblers on several high-throughput sequencing datasets.
Toward More Sensitive Differential Expression Analysis on RNA-Seq Data
 |
Tao Jiang |
As a fundamental tool for discovering genes involved in a disease or biological process, differential gene expression analysis plays an important role in genomics research. High throughput sequencing technologies such as RNA-Seq are increasingly being used for differential gene expression analysis which was dominated by the microarray technology in the past decade. However, inferring differentially expressed genes based on the observed difference of RNA-Seq read counts has unique challenges that were not present in microarray-based analysis. An RNA-Seq based differential expression analysis may be biased against genes with low read counts since the difference between genes with high read counts is more easily detected. Moreover, analyses that do not take into account alternative splicing often miss genes that have differentially expressed transcripts. In this talk, we introduce two novel methods for enhancing differential expression analysis. One uses a markov random field model to integrate RNA-Seq data with coexpression data and the other represents independent alternative splicing events by decomposing the splice graph of a gene into special modules (called alternative splicing modules). Our extensive experiments on simulated data and real data with qPCR validation demonstrate that these enhancements lead to more sensitive differential expression analyses and better classification of cancer subtypes, cell types and cell-cycle phases.
RGB-D Visual Computing: from Low-Level Segmentation to High-Level Scene Understanding
 |
Jianfei Cai |
Commodity RGB-D sensors such as Microsoft Kinect have received significant attention in the recent years due to their low cost and the ability to capture synchronized color images and depth maps in real time. Although the available depth information has been proven to be extremely useful for many visual computing problems, there are still challenges remaining on finding the best way to harness the low-resolution, noisy and unstable depth data and to complement the existing methods using RGB data alone. In this talk, I will show you a series of works from my group ranging from low-level RGB-D image/video segmentation to high-level deep learning based multi-modal feature learning for scene understanding.
Brain Morphological Shape Markers for Alzheimer’s Disease and Vascular
 |
Anqi Qiu |
Structural magnetic resonance imaging (MRI) techniques have been widely used to investigate imaging markers associated with psychiatric disorder and neurodegenerative diseases. In this talk, I will move away from traditional volumetric analysis to sophisticated morphological shape analysis for subcortical structures assessed using conventional T1-weighted MRI. I will demonstrate it in early detection of mild cognitive impairment (MCI), Alzheimer’s disease (AD), and vascular dementia (VaD) using the datasets of ADNI, South Korean ADNI, and Singapore Memory Aging Cognition Study.
Continuum Limits: A Promising Frontier for Large Scale Data Analysis
 |
Alfred Hero |
Many big data applications involve difficult combinatorial optimization that can be cast as finding a minimal graph that covers a subset of data points. Examples include computing minimal spanning trees over visual features in computer vision, finding a shortest path over an image database between image pairs, or detecting non-dominated anti-chains in multi-objective database search. When the nodes are real-valued random vectors and the graph is constructed on the basis of Euclidean distance these minimal paths can have continuum limits as the number of nodes approaches infinity. Such continuum limits can lead to low complexity diffusion approximations to the solution of the associated combinatorial problem. We will present theory and application of continuum limits and illustrate how such limits can break the combinatorial bottleneck in large scale data analysis.
The Role of Statistics in the Big Data Era
 |
Feifang Hu |
With modern technology, it becomes easier and easier to collect data (BIG DATA). Data are not just numbers, but numbers that carry information about a specific setting and need to be interpreted. Statisticians are experts in: (i) producing useful data; (ii) analyzing data to make meanful results; and (iii) drawing practical conclusions. In the BIG DATA era, statisticians are face many new challenges. In this presentation, I will talk about: (1) some new challenges; (2) the importance of statistics in analysising BIG DATA; (3) the role of statisticians in the new era; and (4) the basic skills to become a good staistician. Several examples are used to illustrate the role of statistics in the BIG DATA era.
Information Geometry: Mathematical Foundation for Information Science
 |
Jun Zhang |
Information Geometry is the differential geometric study of the manifold of probability models, and promises to be a unifying geometric framework for statistical inference, information theory, machine learning, etc. Instead of using metric for measuring distances on such manifolds, these applications often use “divergence functions” for measuring proximity of two points (that do not impose symmetry and triangular inequality), for instance Kullback-Leibler divergence, Bregman divergence, f-divergence, etc. Divergence functions induce what is called “statistical structure” on a manifold: a Riemannian metric (Fisher-information) together with a pair of torsion-free affine connections that are coupled to the metric while being mutually conjugate to one another. In turn, they will induce (in special cases) dual coordinates for specifying a probability model, in terms of its natural parameters, expectation parameters, or a mixture thereof. Divergence functions also naturally induce a symplectic structure on the product manifold, giving rise to Hamiltonian dynamics in information systems. More recently, we (with Teng Fei now at MIT) discovered that the statistical structure turns out to be compatible with the so-called Kahler and para-Kahler structure, where metric, symplectic, and complex structures are rigidly interlocked and integrable, and which is encountered in String Theory. This suggests the unifying power of the language of geometry for the foundation of physics and of information. Finally, I use the familiar setting of supervised learning with regularization (“kernel method”) to illustrate how geometric insights about Banach spaces solves the learning-by-sample problem cast as an optimization problem through regularizing the norm of classifier functions in a Reproducing Kernel Banach Space.
Sketchy Decisions: Matrix Optimization with Optimal Storage
|
|
Madeleine Udell |
In this talk, we consider a fundamental class of convex matrix optimization problems with low-rank solutions. We show it is possible to solve these problem using far less memory than the natural size of the decision variable when the problem data has a concise representation. Our proposed method, SketchyCGM, is the first algorithm to offer provable convergence to an optimal point with an optimal memory footprint. SketchyCGM modifies a standard convex optimization method — the conditional gradient method — to work on a sketched version of the decision variable, and can recover the solution from this sketch. In contrast to recent work on non-convex methods for this problem class, SketchyCGM is a convex method; and our convergence guarantees do not rely on statistical assumptions.
Big Data at Didi Chuxing
 |
Jieping Ye |
Didi Chuxing is the largest ride-sharing company providing transportation services for over 300 million users in China. Every day, Didi's platform generates over 70TB worth of data, processes more than 9 billion routing requests, and produces over 13 billion location points. In this talk, I will show how AI technologies including machine learning and computer vision have been applied to analyze such big transportation data to improve the travel experience for millions of people in China.
Deep Learning for Natural Language Processing: Past, Present, and Future
 |
Hang Li |
Deep learning has brought big breakthroughs into many fields in artificial intelligence, including natural language processing. Recent years have observed significant improvements on performances in several tasks of natural language processing, including machine translation, question answering, natural language dialogue, and image retrieval. In this talk, I will introduce research on deep learning for natural language processing (referred to as DL4NLP), conducted at Huawei Noah’s Ark Lab.
The purely neural network based approach (neural processing) has been the main paradigm for DL4NLP. We have developed a number of state-of-the-art models within this approach, for machine translation, question answering, natural language dialogue, and image retrieval. We think, however, that the neural processing approach is not sufficient and a hybrid approach combining neural networks (neural processing) and human defined rules and knowledge (symbolic processing) would be more essential and more powerful. Our major research focus now is exactly the hybrid approach, and we have also developed several models within the hybrid approach, to further improve the performances of existing models or to address new problems which were not covered by existing models.
Optimizing Network Performance for Large-Scale Distributed Machine Learning on Parameter Server Framework
 |
Yonggang Wen |
The Parameter Server (PS) framework is widely used to train machine learning (ML) models in parallel. Many distributed ML systems have been designed based on the PS framework, such as Petuum, MxNet, TensorFlow and Factorbird. It tackles the big data problem by having worker nodes perform data-parallel computation, and having server nodes maintain globally shared parameters. When training big models, worker nodes frequently pull parameters from server nodes and push updates to server nodes, often resulting in high communication overhead. Our investigations show that modern distributed ML applications could spend up to 5 times more time on communication than computation. To address this problem, we propose a novel communication layer for the PS framework named Parameter Flow (PF), which employs three techniques. First, we introduce an update-centric communication (UCC) model to exchange data between worker/server nodes via two operations: broadcast and push. Second, we develop a dynamic value-bounded filter (DVF) to reduce network traffic by selectively dropping updates before transmission. Third, we design a tree-based streaming broadcasting (TSB) system to efficiently broadcast aggregated updates among worker nodes. Our proposed PF can significantly reduce network traffic and communication time. Extensive performance evaluations have showed that PF can speed up popular distributed ML applications by a factor of up to 4.3 in a dedicated cluster, and up to 8.2 in a shared cluster, compared to a generic PS system without PF.
Privacy Preserving Data Publishing: From K-Anonymity to Differential Privacy
 |
Xiaokui Xiao |
The advancement of information technologies has made it never easier for various organizations (e.g., hospitals, census bureaus) to create large repositories of user data (e.g., patient data, census data). Such data repositories are of tremendous research value, due to which there is much benefit in making them publicly available. Nevertheless, as the data are sensitive in nature, proper measures must be taken to ensure that their publication does not endanger the privacy of the individuals that contributed the data.
In this talk, I will review the general methodologies for privacy preserving data publishing, with focuses on three classic notions of privacy (i.e., k-anonymity, l-diversity, and differential privacy) and their variants. I will summarize the techniques developed for each privacy notion, and clarify the pros and cons of each notion. I will also discuss open problems and directions for future research.
Big-Data clustering: K-means versus K-indicators
 |
Yin Zhang |
Clustering is a fundamental data-driven learning strategy. The most popular clustering method is arguably the K-means algorithm, albeit it usually is applied not directly to a dataset as given, but to its image in a transformed space, as is the case in spectral clustering methods. However, as the number of clusters increases, the K-means algorithm experiences a deteriorating performance even under ideal conditions. In this work, we propose a new clustering model, called K-indicators, and construct a non-greedy, non-random, parameter-free algorithm for it. On a collection of synthetic datasets, the proposed method continues to recover the ground truth long after the K-means algorithm has stopped delivering. Experimental results on real datasets show that the new method can provide better or competitive solution quality in less time than the K-means algorithm can. In addition, it provides valuable a posteriori information about clustering quality and uncertainty in the absence of ground truth.
Querying, Exploring and Mining Geospatial Social Media Data
 |
Gao Cong |
Massive amounts of geo-textual data that contain both geospatial and textual content are being generated at an unprecedented scale from social media websites. Example user generated geo-textual content includes geo-tagged micro-blogs, photos with both tags and geo-locations in social photo sharing websites, as well as points of interest (POIs) and check-in information in location-based social networks. This talk presents recent results by the speaker and his colleagues on querying, exploring, and mining geo-textual Data from Social Media feeds. The talk will cover (1) indexing and querying geo-textual data, (2) querying geospatial social media data streams, (3) exploratory search on geo-textual data, and (4) context-aware POI recommendations.
Cross-Object Coding and Allocation (COCA) in Distributed Storage Systems
 |
Liuqing Yang |
Distributed storage systems (DSS) are widely employed at data centers and in sensor networks, where storage node failures are inevitable. With the increasing utilization of inexpensive commodity storage hardware, failures of storage nodes are often treated as a norm rather than unexpected accidents. Structured redundancy is thereby introduced to DSS via various coding schemes. While efficiently accounting for storage node failures, such redundancy often leads to high storage overhead. Additionally, the storage allocation could also impact the data reliability in DSS. In this talk, we will review the fundamentals of DSS and explore the benefit of coding across multiple data objects. In addition to the mathematical investigation on the reliability of the cross-object coding and allocation (COCA), we will also discuss the tradeoff between data reliability and data retrieval complexity associated with COCA.